 > Telebib2-XML - XSD Schema
> Telebib2-XML - XSD Schema
SYNTAX DEPENDENT COMPONENTS
Introduction - Development status overview
Introduction - Development status overview

|
> Telebib2-XML - XSD Schema
|
SYNTAX DEPENDENT COMPONENTS
Introduction - Development status overview |
|
| Things as of today | |
|
|
| (21.06.2022 - within this "approach B" the XSD material as published...) | |
|
The schemas have now been published for the release-year 2023 too. That main schema is available at the URL www.telebib2.org/Namespace/2023/Tb2Schema_01.xsd. These schemas are available, beside those of the release-year 2022. That main schema is available at the URL www.telebib2.org/Namespace/2022/Tb2Schema_01.xsd. And these schemas are available, beside those of the release-year 2021. That main schema is available at the URL www.telebib2.org/Namespace/2021/Tb2Schema_01.xsd. |
|
| (29.11.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have now been published for the release-year 2022 too. That main schema is available at the URL www.telebib2.org/Namespace/2022/Tb2Schema_01.xsd. These schemas are available, beside those of the release-year 2021. That main schema is available at the URL www.telebib2.org/Namespace/2021/Tb2Schema_01.xsd. |
|
| (12.08.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have been published once more in a newer version. The schemes added (M0151_01.xsd, M0213_01.xsd and M0421_01.xsd) allow for claims certificates exchanges as historically implemented by some parties... |
|
| (21.06.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have been published once more in a newer version. For the IDD+... qualified segment, for a series of recently added qualifier-values, the XML denominator had not been added. |
|
| (11.06.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have (again) been published in a newer version. There were some places where the logic (deriving the schema content from the Edifact MIG material) as implemented was not fully OK. The correction involved changes in the transforming/deriving logic. Successive MIGs were slightly misunderstood. The problem was found by/in the transformation of the DPT_DAM_DOD030_201501 MIG. This is why we now changed, in the MIG visualisation web-page, the wording "Extendible with one of..." into "Completed/refined with one of..." which we think expresses somewhat better what is actually happening. |
|
| (04.06.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have been published in an even newer version. There were some places where the logic (deriving the schema content from the Edifact MIG material) as implemented was not fully OK. The correction involved (minor) changes in that MIG material, and changes in the transforming/deriving logic. Especially segmentgroups qualified and their corresponding XML/JSON denominators were concerned. |
|
| (05.05.2021 - within this "approach B" the XSD material as published...) | |
|
The schemas have been published in a newer version. There were some errors, especially in the representation of some risk-objects types, which were simply missing. And the same so for other segmentgroups qualified - corresponding XML/JSON denominators were simply missing. |
| (21.04.2021 - within this "approach B" the XSD material as published...) | |||||||||||||||||||
|
The schemas have been published in a newer version. There were some errors, especially in the assembly of risk-objects and guarantees as present in the schemas, and derived from their corresponding edifact representations. |
|||||||||||||||||||
| (16.04.2021 - within this "approach B" the XSD material as published...) | |||||||||||||||||||
|
The schemas have been published in a newer version. There were some errors, especially in the multiplicity of risk-objects and guarantees. |
|||||||||||||||||||
| (21.01.2021 - within this "approach B" getting back from XML (or JSON) to the EDIFACT-denominators...) | |||||||||||||||||||
(An implicated party asked for a tool allowing the positionning of some XML (or JSON) Tag within the (former) EDIFACT context or approach, so the "reverse way".)On the following page we simply list all XML Tags as set up within the XML Schema, and which were derived from those same EDIFACT Tags and other Data Elements. |
|||||||||||||||||||
| (06.10.2020 - this renewed initiative, the "approach B" becoming the final choice.) | |||||||||||||||||||
(Recent contacts with some major implicated party now confirm "approach B" as our final option.)
|
|||||||||||||||||||
| (04.02.2020 - this renewed initiative, from a "approach" A to another "approach B".) | |||||||||||||||||||
(Upto 18.12.2019 the new initiative has firstly been conceived as what we call now the "approach A". Recent contacts with some major implicated party now lead to another "approach B".)
That is in the Exchange Units list, in the Segments list, in the Composite Data Elements list, in the Data Elements list. In the Qualifier/Code lists page, accessing the details of X052 ("Object qualifier") will offer only the "approach A" XML/JSON tags. In the Segments list page, accessing the details of the ROD segment, and there accessing the details of that same X052, will offer both the "approach A" and "approach B" XML/JSON tags. Ultimately, it is expected for only the "approach B" to persist - but in this stage of things we prefer to hold on to the both. Note also that, for our Telebib2 Coded Values code-lists, we already offer a "Technical label for XML / JSON usage". Currently neither approach A nor approach B do already use these alternative values. |
|||||||||||||||||||
| (18.12.2019 - this renewed initiative, continued.) | |||||||||||||||||||
|
(We continue designing a transition towards XML and JSON.) Progress has been made and is published in our Blog dated 18/12/2019. The XML is now transformed back into our EDI. Meaning the information can go forth and back into the both formats. This is what is necessary for the expected transitional period, as needed by the different actors in the field. This is for now still to be considered as "non final" and "work under construction". |
|||||||||||||||||||
| (20.11.2019 - this renewed initiative, continued.) | |||||||||||||||||||
|
(We continue designing a transition towards XML and JSON.) Some progress has been made and is published in our Blog dated 20/11/2019. The one step further is the replacement of the almost 100% Edifact alike XML-tags by labels in some "technical english" and hence becoming more readable by the development community. The same tags can be used within the similar JSON constructs. The Codes lists pages and the Edifact Directory pages already do show such labels under a header alike "Technical label for XML / JSON usage". This is for now still to be considered as "non final" and "work under construction". |
|||||||||||||||||||
| (07.11.2019 - a new colorscheme for a renewed initiative.) | |||||||||||||||||||
|
(07/11/2019; a renewed initiative is ongoing. We talk about a transition towards XML and JSON.) This is for now published on this pre-existing XML-page. The idea is to stick very close to what has been developed and published in our Blog in the period 06-08/12/2016. The one step further is to replace the almost 100% Edifact alike XML-tags by labels in some "technical english" and hence becoming more readable by the development community. The same tags can be used within the similar JSON constructs. The Codes lists pages and the Edifact Directory pages already do show such labels under a header alike "Technical label for XML / JSON usage". This is for now to be considered as "non final" and "work under construction". |
|||||||||||||||||||
|
(For those interested; see the historical info further down...) (Info last updated : 20.12.2018) |
|||||||||||||||||||
|
This page should give you an overview of the developments towards XML ... (And yes indeed; this page too should be using even more a blue color scheme - as explained on the page introducing the UN/Edifact syntax...) It is important to know this is an ongoing process which did not yet deliver approved results. Hence, one may not yet start building implementations based on the material published. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2018 The model, as documented by the Enterprise Architect tool is actually still the 2015's version. This model (2015's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2015 version", and have been modified manually into the "Namespace 2018 version" the sole difference being the change from http to https. (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes, we re-elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. 20/12/2018 - KID for PRIIPs (Key Information Document for Packaged Retail Insurance based Investment Products) Aside of the above, we have been involved in the CEN/TC 445 (Centre Européen de Normalisation; the European Standardization Organisation - Technical Committee) "Digital Information Interchange in the Insurance Industry" where we prepared a potential "work item" project for the develoment of an XML representation of such KID for PRIIPs. That "work item" did not get the necessary country support (only 3 countries would actively contribute) and was stopped. In reality, what had been presented there as a "to do", was a finalised analysis with a resulting schema. The basis is the Regulation (EU) 1286/2014 of 26/11/2014 KIDs for PRIIPs. These are the "Commission delegated Regulation 8/3/2017 draft 1473" and the corresponding "Annexes 1 to 7", both containing some mark-up added and indicating the relevant elements for the XSD schema development. This is the XSD schema KID.xsd. And these are two examples af the resulting XML files:
This a more real-life example we found for a (non-belgian) insurer. Note how we added into the pdf-file the xml-file representing the similar content. (You must download/open the pdf-file with the tool offering such functionality e.g. Adobe Acrobat Reader DC.) (*) This is a technique which has been proposed/used in other environments. The approach is quite attractive, as it allows for the one and the same organisational chain delivering both the "paper document" and the "structured information". The receiving party then has the liberty to use/exploit the one and/or the other. (*) Picture of such functionality : 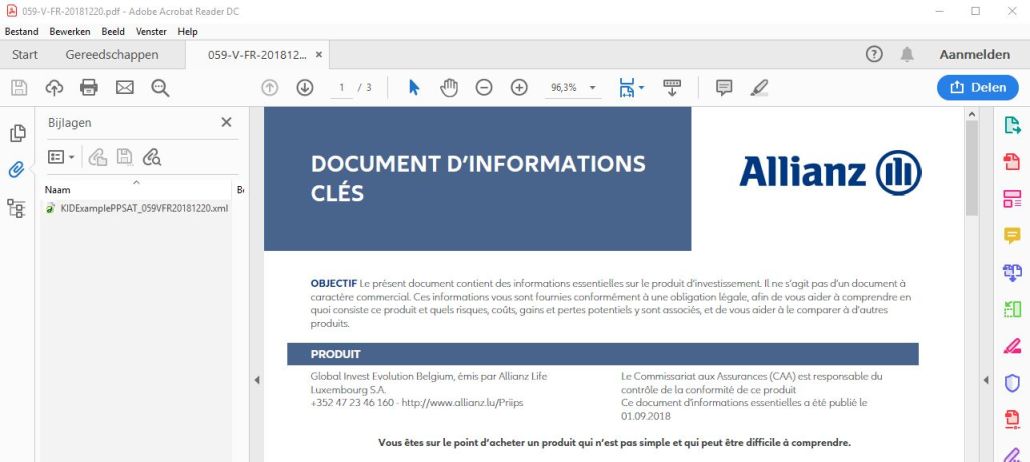 |
|||||||||||||||||||
|
Telebib2 XML Namespace 2015 The model, as documented by the Enterprise Architect tool. This model (2015's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2015 version ". (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes (still upon the 2014 versions), we elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2014 The model, as documented by the Enterprise Architect tool. This model (2014's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2014 version ". (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes, we elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2013 The model, as documented by the Enterprise Architect tool. This model (2013's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2013 version ". (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes, we elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2012 The model, as documented by the Enterprise Architect tool. This model (2012's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2012 version ". (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes, we elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2011 The model, as documented by the Enterprise Architect tool. This model (2011's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, non-standard EA functionality (*)) 4 XML schemes : - Entities.xsd - DataTypes.xsd - Codelists.xsd - BasicTypes.xsd These 4 schemes are at the core of our "Namespace, 2011 version ". (*): We wrote our own versions of the "code-generating-templates" as offered by EA. Based upon these schemes, we elaborated some examples of xml files (or strings) which seem to validate our approach. These examples are messages about some person, contract, premium notification, accounting slip (or bordereau), current account statement, and finally about some claim. We also added an example of a message about some medical assessment report. |
|||||||||||||||||||
|
Telebib2 XML Namespace 2010 The model, as documented by the Enterprise Architect tool. This model (2010's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated, standard EA functionality) 3 XML schemes : - Entities.xsd - Codelists.xsd - BasicTypes.xsd These 3 schemes are at the core of our "Namespace". |
|||||||||||||||||||
|
Telebib2 XML Namespace 2009 The model, as documented by the Enterprise Architect tool. This model (2009's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated functionality) 3 XML schemes : - Entities.xsd - Codelists.xsd - BasicTypes.xsd These 3 schemes are at the core of our "Namespace" : - "http://www.telebib2.org/Namespace/2009/Entities" (download the schemafile) - "http://www.telebib2.org/Namespace/2009/Codelists" (download the schemafile) - "http://www.telebib2.org/Namespace/2009/BasicTypes" (download the schemafile) |
|||||||||||||||||||
|
Telebib2 XML Namespace 2008 The model, as documented by the Enterprise Architect tool. This model (2008's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. From this model have been derived (by automated functionality) 3 XML schemes : - Entities.xsd - Codelists.xsd - BasicTypes.xsd These 3 schemes are at the core of our "Namespace" : - "http://www.telebib2.org/Namespace/2008/Entities" (download the schemafile) - "http://www.telebib2.org/Namespace/2008/Codelists" (download the schemafile) - "http://www.telebib2.org/Namespace/2008/BasicTypes" (download the schemafile) |
|||||||||||||||||||
| Historical info | ||
|
11/03/2011 milestone : |
We think we now came to some level of maturity, and decided to start publishing our work afresh. We here retain what we (uptoo now) presented as the "Things as of today", and this as "archived" material. |
|
|
The Model 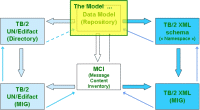 |
The model, as documented by the Enterprise Architect tool. This model (current 2011's version) can be downloaded here. Enterprise Architect exists in a free of charges version with restricted functionality, which can be downloaded here. |
|
|
National language view 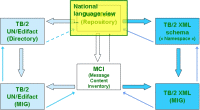
|
The documentation generated by the Enterprise Architect tool is organised around the technical namings of the things modelled. This is generally considered OK for the more technically skilled (ICT-)people within our organisations. But we think that those who are more on the business-side can experience some difficulties when confronted with such "techies language". For this reason, we offer an alternate view, where you can see on a first screen : - in the center : the objects or "Classes"; - on the leftside : the more general object or "Superclass" or "Generalization" (by clicking the «- in the center-column); - on the rightside : the more specific objects or "Subclasses" or "Extensions" (by clicking the -» in the center-column); - in the lower part of the 3 columns, the details of each object (the "Attributes" and the "Associations") can be viewed (by clicking the object's name); - at the bottom, definitions can be viewed (by clicking one of the ? ); - (clicking the «- in the leftside-column) check if there is an even higher "Generalization"; - (clicking the-»in the rightside-column) check if there are even deeper "Extensions"; - (clicking the En Fr Ge Nl in the center-column) jump to another language but stick to the same object; - and finally, in the lower part of the 3 columns, for the attributes: you can jump to the codelist, which is a second screen (*); - and for the associations: you can jump to the associated class. (*) That secondary alternate view, offers : - in the center : the codelists; - on the leftside : the object(s) and attribute(s) which use this codelist (by clicking the «- in the center-column); - on the rightside : the possible values (by clicking the -» in the center-column); - in the lower part, an overview including versioning information (by clicking the codelist's name); - at the bottom, definitions can be viewed (by clicking one of the ? ); - and again, you can jump to the different languages whilst sticking to the same codelist. (This view is based on the contents of a TB2Model.mdb file, which can be downloaded here.) |
|
|
Model based MCI's 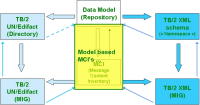
|
You can take a look at MCI's build on top of that Model. The first fully elaborated examples are : - ROD060 (version 1, status 2); - ROD001 (version 1, status 2). We are working on ROD001 (version 2, status 2). You first get a "Simple View", and must click through to "MCI as from the Model" where you will see how each MCI-element is related to some element within the Model. (Again, as business people might find it difficult to read the technical terms as coming from the Model, they can change to the same view in Fr or Nl.) Finally, you can click through to "MCI against derived EDI" where you will see how each MCI-element relates to it's UN/Edifact MIG counterpart. (Here, only ROD060 has already been elaborated.) (This view is based on the contents of some tables from the TB2Model.mdb file.) |
|
|
Telebib2 UN/Edifact MIG's 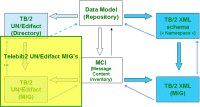
|
You can take a look at the Telebib2-UN/Edifact MIG's, and see how they are connected to the MCI's : . Again, ROD06007 is a first fully elaborated example... Let's agree on this view being oriented much more to the technical people, and much less to the business people. We are now ready to start deriving messaging in some other syntax... (This view is based on the contents of some tables from the TB2Model.mdb file.) |
|
|
Telebib2 XML Namespace 2008 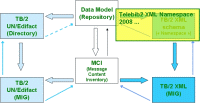
|
From the model are being derived (by automated functionality) 3 XML schemes : - Entities.xsd - Codelists.xsd - BasicTypes.xsd These 3 schemes are at the core of our "Namespace" : - "http://www.telebib2.org/Namespace/2008/Entities" - "http://www.telebib2.org/Namespace/2008/Codelists" (download the schemafile) - "http://www.telebib2.org/Namespace/2008/BasicTypes" (download the schemafile) And we continued developing a "Namespace 2009" (Entities, Codelists, BasicTypes). And we continued developing a "Namespace 2010" (Entities, Codelists, BasicTypes). And we are currently working on a "Namespace 2011" (Entities, DataTypes, Codelists, BasicTypes). |
|
|
XML MIG ROD060 v1 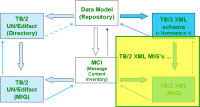
|
The buildingblocks as offered by this "Namespace 2008 " have been used within the Altova XMLSpy tool, where, guided by the corresponding MCI, the actual Message Implementation Guide has been constructed... |
|
|
24/02/2011 continued : |
We continue working on our current 2011 version of the model. The model, as documented by the Enterprise Architect tool, in it's final 2010 version, in html, or as a download, and the light version of Enterprise Architect. |
|
|
26/01/2010 continued : |
We continue working on our current 2010 version of the model. The model, as documented by the Enterprise Architect tool, in it's final 2009 version, in html, or as a download, and the light version of Enterprise Architect. |
|
|
28/04/2009 continued : |
We returned from the 14th UN/CEFACT Forum (20-24 april 2009, Rome - Italy) with some, at least for us, new information. The "UN/CEFACT's Modeling Methodology" (UMM) and the "Conceptual Business Document Modeling using UN/CEFACT's Core Components" are things that can be read about on the UMM Developoment Site. We have the impression that this material shows off a new level of maturity being reached. The material also confirms our choice of the Enterprise Architect tool. We will now see how we can align our own work even more with these developments. This does not alter our projected route as for the representation of our EDI-messages within the Altova-Mapforce tool. |
|
|
16/02/2009 continued : |
The current 2009 version of the model: - contains material which reflects the "filters" (domains versus guarantees / objects / policytypes), see the package called "SectoralFilters". - has been reworked in preparation of the usage of the resulting XSD-schemes within the Altova-Mapforce tool. The goal being the representation of our EDI-messages within this Altova-Mapforce environment, plus the representation of our XSD-schemes, plus the mapping in between the both. Such approach changes our conceptual idea's in the sence that it replaces our table-based work with work based on the usage of even more professionally adapted tools. We now prepare the material, which permits the representation of our EDI-messages within the Altova-Mapforce tool, for publication through these pages. The "National language view" now not only shows the attributes of some class, but also the associations from the one class to the other, and it has been made possible to to follow these associations by "jumping" from the one to the associated class. The model, as documented by the Enterprise Architect tool, in it's final 2008 version, in html, or as a download, and the light version of Enterprise Architect. |
|
|
15/07/2008 continued : |
Codelists : until now, in the newly developed Model, the Name of a codelistvalue showed significance but hence was different from the TB2CodelistValue which in turn was represented by a tagged value. This was a conceptual choice and was conceptually one step too far for our today's user community. Resolution : the contents of Name and TB2CodelistValue have been swapped, and the tag TB2CodelistValue has been renamed to AlternativeValue. Then all depending queries and webpages have been checked. |
|
|
25/06/2008 Xml Workgroup session : |
Session extended to a larger public, where the current material will be presented, including Q&A (time spent on questions and answers). The goal of this session is for our distinct market participants (insures, brokers, package vendors and the like) in finding the necessary and sufficient information with which they can then make their own benefits/costs analysis. This analysis will or will not allow them to take the step towards such Xml syntax. |
|
|
25/04/2008 continued : |
This month, we concentrated on the codelists. The links as offered since 26/03/2008 are still valid, but these now give access to views covering wat we need, including codelists and their versioning. Still, ROD06007 is a first fully elaborated example... Have to be added too, some views on the codelists themselves, including their value-lists, definitions, version- and depreciation-information. |
|
|
10/04/2008 Xml Workgroup session : |
The concepts as developed upto this point, have been validated as being sufficiently complete to make it possible to estimate : - the development costs of the necessary conversion-functionality, - the complexity of developments, triggered by, and/or based upon these Xml structures. |
|
|
28/03/2008 continued : |
You can take a look at the Telebib2-UN/Edifact MIG's, and see how they are connected to the MCI's : here. Again, ROD06007 is a first fully elaborated example... We are now ready to start deriving messaging in some other syntax... |
|
|
27/03/2008 continued : |
You can take a look at MCIs build on top of that Model : here. ROD060 is a first fully elaborated example... |
|
|
26/03/2008 continued : |
The Enterprise Architect tool from Sparx Systems proves being quite effective. You can take a look at the html-documentation generated here. Basically, that documentation is build as a tree-view on info-elements which have been assigned names which might seem somewhat peculiar to the regular business-user. This is why we offer the business-user access to the same information-tree, in his native language. By combining both views, each user should be able to find his way within the model... |
|
|
25/01/2008 continued : |
Another tool is being used; see our (non-final) results here : another approach. |
|
|
25/10/2007 Xml Workgroup session, and continued work: |
The Telebib co-ordinator presented the idea of a data-model: - which stands at the centre, - of which some syntax is a derivative, - which is the basic working material for the Normalisation Workgroup. This presentation has been given at today's XML Workgroup meeting. It depicts the situation as-is, versus what is seen as a possible goal. |
|
|
05/10/2007 continued : |
French and Dutch business terms have been added into a Telebib2BaseV03.xsd file. The links (under 27/09/2007) give now results including these translations. The schema-oriented link (under 03/09/2007) now offers documentation including these translations too, but the model-oriented link does not - this is exactly why the exercise dated 27/09/2007 has been made... |
|
|
27/09/2007 some other tests : |
Normalisation - Technical namings Normalisation - French namings Normalisation - Dutch namings These links might ask some time to fully open, depending on your system-speed... |
|
|
03/09/2007 |
We are working on the development of some xsd files. We can give you a preview on what we do; take a look at our schema which offers the basic message-building blocks. Look at it by means of a schema-oriented documentation, or by means of a model-oriented documentation... |
|
|
24/05/2007 Xml Workgroup session : |
We decided we should deliver the distinct market actors the basic information which allows them to estimate the benefits and costs of the implementation of such a second syntax. - And this alongside the existing and already implemented syntax, hence including the conversion from/to the existing syntax to/from the new syntax. - Such conversion functionality might be developed and provided by some central market actor. That basic information consists of a sufficiently coherent set of: - on the one hand the existing Telebib2 UN/Edifact defining elements, - on the other hand the to be developed Xml defining elements, - and the concepts which permit univocal (unequivocal, unambiguous) links between the both. |
|
|
22/03/2007 Xml Workgroup session : |
This session we discussed : - the tools (dBMain) and the material (DTD) as currently used within the Telebib center, versus the Altova tools (XMLSpy, UModel, ...), - the results of, and conclusions based upon a comparison of Acord material with Telebib2 material, - meanwhile we received from different parties signals indicating the major importance attached to staying as close as possible to our today's Telebib2 standards. |
|
|
15/02/2007 Xml Workgroup session : |
The Xml Workgroup comes under the Mixed Observation Committee (CMS - Commission Mixte de Suivi / GOC - Gemengde OpvolgingsCommissie), and does not report directly to the Normalisation Workgroup. The job as given the Xml Workgroup has been set out as : - to determine what is being asked for, - to propose the possible answers, - to estimate the benefits and costs incurred by the distinct market participants, - to develop a planning. This first session of our Xml Workgroup, we looked at what happens internationally, including the status alike within Acord (Association for Cooperative Operations Reasearch & Development). |
|