Table de matière
3.1. Latin-1
3.2. Caractères réservés
4.1. Structure globale
4.2. Structure d'une rubrique
4.3. Structure d'un segment
4.4. Structure d'un élément de données
5.1. Exclusion de segments
5.2. Ommission d'éléments de données
5.3. Troncation d'éléments de données
5.4. Ommission d'éléments de données constitutifs
5.5. Troncation d'éléments de données constitutifs
6.1. Segment XGH, en-tête d'un groupe d'unités d'échange
6.2. Segment XGT, fin d'un groupe d'unités d'échange
6.3. Segment XEH, en-tête d'une unité d'échange
6.4. Segment XET, fin d'une unité d'échange
6.5. Segment XRH, en-tête d'une rubrique
6.6. Segment XRT, fin d'une rubrique
La présente norme comprend les règles qui se situent au niveau de l'application pour la structuration des données de l'utilisateur et des données de service associées pour l'échange d'information.
La syntaxe décrite est basée sur l'ISO 9735, adoptée par la Commission Economique pour l'Europe des Nations-Unies ( CEE/ONU ) comme règles de syntaxe pour l'échange électronique de données pour l'administration, le commerce et le transport ( EDIFACT ).
Ceci est la version 1 de la présente norme.
Cette syntaxe sera d'application pour tous les échanges de données dans le cadre de l'architecture Assurnet2 impliquant des partenaires différents ( par exemple le log-deal, le nouveau bloc retour, ... )
3.1. Latin-1
A moins que les partenaires de l'échange conviennent d'utiliser un autre jeu de caractères, Latin-1 (ISO 8859-1) est utilisé à l'exception du charactère NUL (hexadécimal : 00). Ce jeu de caractères contient tous les caractères utilisés dans les langues de l'Europe Occidentale parmi lesquelles figurent le Français et le Néérlandais.
Vu son rôle particulier dans la plupart des environnement de développement, le charactère NUL (hexadécimal : 00) ne peut pas être utilisé au sein d'un échange.
3.2. Caractères réservés
Les caractères suivantes sont réservés pour des utilisations spécifiques :
Les segments doivent figurer dans l'ordre indiqué ci-dessous dans un groupe d'unités d'échange.
Plusieurs unités d'échange peuvent figurer dans un groupe.
Plusieurs rubriques peuvent figurer dans une unité d'échange.
Une rubrique est constituée de segments.
Un segment est composé d'éléments de données simples et / ou composites.
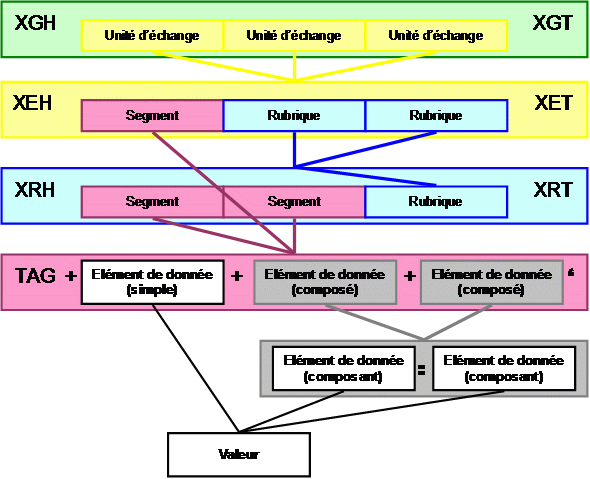
4.1. Structure globale
Un groupe d'unités d'échange contient :
4.2. Structure d'une rubrique
Une rubrique contient :
4.3. Structure d'un segment
Un segment contient :
4.4. Structure d'un élément de données
Un élément de données contient :
Un élément de données simple ne contient qu'une seule valeur d'élément de données.
Un élément de données composite contient plus d'un élément de données constitutif.
Un élément de données constitutif ne contient qu'une seule valeur d'élément de données.
Il n'y aura pas de séparateur d'éléments de données constitutifs après le dernier élément de données constitutif et pas de séparateur d'éléments de données après le dernier élément de données.
Les caractères non significatifs des éléments de données doivent être omis. Ces caractères ne sont pas transmis : par exemple, les zéros précédant une valeur numérique ou les caractères complètant une valeur alphanumérique.
A noter cependant qu'un zéro unique devant un signe décimal est significatif et qu'un zéro peut être significatif si cela est indiqué dans la spécification des éléments de données.
Les règles précisées ci-après s'appliquent pour la compression des unités d'échanges.
Dans les exemples ci-dessous, TAG représente l'en-tête de segments, DE un élément de données et CE un élément de données constitutif.
5.1. Exclusion de segments
Les segments ne comportant pas d'éléments de données doivent être omis (y compris leurs en-tête).
5.2. Omission d'éléments de données
Les éléments de données sont identifiés par leur position au sein d'un segment ainsi que défini par le répertoire des segments du TELEBIB. Si un élément de données est omis et est suivi d'un autre élément de données, un caractère séparateur d'élément de données est transmis en lieu et place de l'élément de données considéré.
TAG+DE+DE+++DE+DE+DE' Deux éléments de données sont omis.
5.3. Troncation d'éléments de données
Si un ( ou plusieurs ) élément(s) de données est omis à la fin d'un segment celui-ci peut être tronqué par le caractère de fin de segment ; dans ce cas les caractères séparateurs d'éléments de données omis ne sont pas transmis.
TAG+DE+DE+++DE' en reprenant l'exemple de 5.2., les deux derniers éléments ont été omis et le segment a été tronqué.
5.4. Omission d'éléments de données constitutifs
Les éléments de données constitutifs sont identifiés par leur position au sein d'un élément de données composite. Si un élément de données constitutif est omis, un caractère séparateur d'élément de données constitutif est transmis en lieu et place de lélément de données constitutif considéré.
TAG+DE+CE:CE+CE:::CE' Deux éléments de données constitutifs sont omis dans le troisième élément de données.
5.5. Troncation d'éléments de données constitutifs
Si un ( ou plusieurs ) élément(s) de données constitutif est omis à la fin d'un élément de données composite celui-ci peut être tronqué par le caractère séparateur d'éléments de données ; dans ce cas les caractères séparateurs d'éléments de données constitutifs omis ne sont pas transmis.
TAG+DE+CE+CE' en reprenant l'exemple de 5.4., le dernier élément de données constitutif du premier élément de données composite est omis ainsi que les trois derniers éléments de données constitutifs du deuxième élément de données composite. Dans les deux cas l'élément de données composite a été tronqué, cela est indiqué dans le premier cas par le caractère séparateur d'éléments de données et dans le deuxième cas par le caractère de fin de segment.
6.1. Segment XGH, en-tête d'un groupe d'unités d'échange
6.1.1. Fonction
6.1.2. Contenu
Numéro de version de la syntaxe ( obligatoire )
Identification de l'émetteur ( obligatoire )
Identification du destinataire ( obligatoire )
Type du groupe
6.2. Segment XGT, fin d'un groupe d'unités d'échange
6.2.1. Fonction
6.2.2. Contenu
Numéro de version de la syntaxe ( obligatoire )
6.3. Segment XEH, en-tête d'une unité d'échange
6.3.1. Fonction
6.3.2. Contenu
Type d'unité d'échange ( obligatoire )
Numéro de version de l'unité d'échange ( obligatoire )
Code unité d'échange / action
Identification de l'unité d'échange auprès de l'émetteur
Identification de l'unité d'échange auprès du destinataire
Domaine
Code retour applicatif
Code erreur
Code conversion devise
Date d'émission de l'unité d'echange
Détails concernant l'émission de l'unité d'échange
6.4. Segment XET, fin d'une unité d'échange
6.4.1. Fonction
6.4.2. Contenu
6.5. Segment XRH, en-tête d'une rubrique
6.5.1. Fonction
6.5.2. Contenu
6.6. Segment XRT, fin d'une rubrique
6.6.1. Fonction
6.6.2. Contenu
Cette section décrit formellement la grammaire de la syntaxe Assurnet2 en notation BNF.
exchange est la racine de l'arbre et correspond au groupe d'unité d'échange dans la description textuelle.
exchange:
exchange-group-header exchange-unit-list exchange-group-trailer
exchange-group-header:
XGH+ syntax-version + address + address '
XGH+ syntax-version + address + address + string '
exchange-group-trailer:
XGT+ syntax-version '
exchange-unit-list:
exchange-unit
exchange-unit-list exchange-unit
exchange-unit:
exchange-unit-header segment-list block-list exchange-unit-trailer
exchange-unit-header:
XEH+ string + exchange-unit-version '
XEH+ string + exchange-unit-version + string '
XEH+ string + exchange-unit-version + stringopt + string '
XEH+ string + exchange-unit-version + stringopt + stringopt + string '
XEH+ string + exchange-unit-version + stringopt + stringopt + stringopt + string '
exchange-unit-trailer:
XET+ string '
segment-list:
segmentopt
segment-list segment
block-list:
blockopt
block-list block
segment:
tag + data-element-list '
block:
block-header id-segment segment-list block-list block-trailer
block-header:
XRH+ number '
block-trailer:
XRT+ number '
id-segment:
segment
tag:
tag-letter tag-letter tag-letter
data-element-list:
data-element
data-element-list list-plus data-element
list-plus:
+
list-plus +
data-element:
simple-data-element
composite-data-element
simple-data-element
string
number
composite-data-element:
simple-data-element
composite-data-element list-colon simple-data-element
list-colon:
:
list-colon :
syntax-version:
1
01
exchange-unit-version:
digit
digit digit
address:
string
string : string
string:
init-string
string list-spaceopt init-string
init-string:
not-reserved
escape-sequence
list-space:
espace
list-space espace
number:
digit-list
- digit-list
digit-list:
digit
digit-list digit
digit:
un de0 1 2 3 4 5 6 7 8 9
escape-sequence:
?+
?:
?'
??
tag-letter:
un deA B C D E F G H I J K L M N O P Q R S T U V W X Y Z
not-reserved:
un caractère du jeu Latin-1 sauf + : ' ?, le zéro binaire et l'espace